

데이터 베이스 기본 개념
쿼리
데이터 베이스 기본 개념
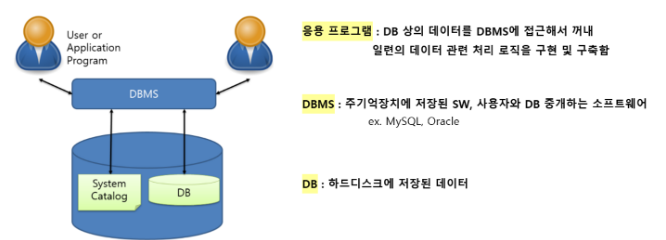
1) 데이터베이스 (DB) 개념
- 일정한 규칙으로 구조화되어 저장된 데이터의 모음
[ 데이터베이스의 특징 ] (4)
1) 실시간 접근성
실시간 처리에 대한 응답 가능
2) 지속적인 변화
데이터베이스 상태가 동적이다.즉, 새 데이터 삽입/삭제/갱신 등 항상 최신의 데이터를 유지한다.
3) 동시 공유
다수의 사용자가 동시에 같은 내용의 데이터 이용 가능
4) 내용에 따른 참조
데이터베이스에 있는 데이터 참조 시 사용자가 요구하는 데이터 내용 기준 찾음 </aside>
2) 데이터베이스의 종류

(1) 관계형 데이터베이스 | RDBMS
: 모든 데이터를 2차원 테이블 형태 (행과 열)로 데이터 저장하는 데이터 베이스
: 테이블 형태로 데이터 관리
: SQL 언어 사용하여 데이터 조작 | (SQL : Structured Query Language)
ex. MySQL, Oracle
장점 : 스키마에 맞춰 데이터 관리하므로 ‘데이터 정합성’ 보장
단점 : 시스템 커질수록 쿼리 복잡해져 성능 저하됨 (Scale-out 어렵고, Scale-up만 가능)
(2) NoSQL 데이터베이스 | Not Only SQL
: 데이터 간의 관계를 정의하지 않아 스키마 없이 자유롭게 데이터 관리하는 데이터베이스
: 컬렉션 형태로 데이터 관리
: SQL을 사용하지 않는 데이터베이스
ex. MongoDB, redis
장점 : 스키마 없이 Key-value 형태로 데이터 관리하니 자유롭다.
단점 : 데이터 중복 발생하며, 중복된 데이터 변경 시 수정을 모든 컬렉션에서 수행해야 한다.
스키마 존재하지 않아서 명확한 데이터 구조 보장하지 않아 데이터 구조 결정 어려울 수 있다.
❓ 그렇다면 RDBMS와 NoSQL은 각각 어느 경우에 적합한가 ?
RDBMS : 데이터 구조 명확하고 데이터의 일관성, 신뢰도 보장이 우선일 때 사용 권장
→ 데이터 변경 자주 일어나는 시스템에 적합, 정형화된 데이터에 적합
NoSQL : 정확한 데이터 구조 알 수 없고 데이터 처리 속도나 유연성, 확장성 우선일 때 사용 권장
→ 데이터 중복/수정 많이 일어나지 않는 시스템에 적합, 비정형화된 데이터에 적합
→ Scale-out 가능하다는 장점 O 확장성 중요하고 DB를 Scale-out 해야 하는 시스템에 적합
릴레이션 (relation)
→ 관계형 DB 의 릴레이션 = ‘테이블’
→ NoSQL DB의 릴레이션 = ‘컬렉션’
3) 데이터베이스의 무결성 제약 조건
- 즉, 데이터의 정확성,일관성 보장하기 위해 (저장/삭제/수정)에 제약하는 조건이다.
1) 개체 무결성 (Entity Integrity)
- 각 릴레이션의 기본키 PK는 중복X, NULL X
- 각 릴레이션 당 하나의 PK는 존재해야 한다.
2) 참조 무결성 (Referential Integrity)
- 외래키값은 NULL이거나 참조 중인 릴레이션의 PK값과 일치해야 한다.
- 이로써 외래키의 무결성을 보장한다.
3) 도메인 무결성 (Attribute Integrity)
- 속성들의 값은 정의된 도메인에 속한 값이어야 한다.
→ 그 중에서도 관계형 DB를 더 자세히 보자.
[관계형 데이터베이스의 구성]
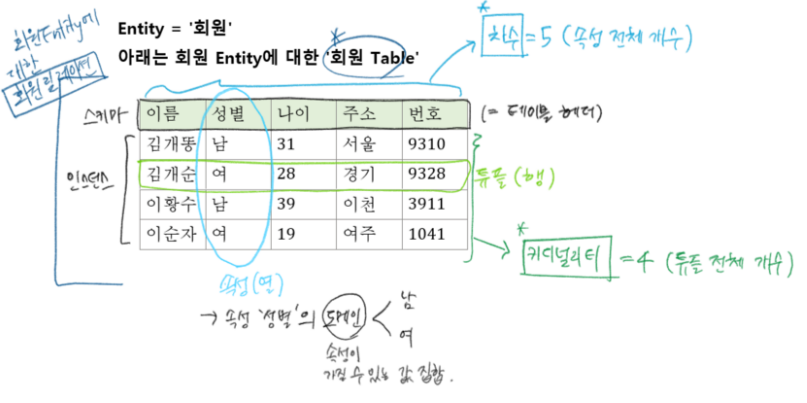
1) 엔티티 | Entity
- 자체로 여러 개 속성을 지니는 명사
- ex. 회원 Entity → 속성(id, 이름, 주소)
2) 릴레이션 | relation (=테이블)
- 관계형 DB의 릴레이션 = 행과 열로 구성된 테이블 의미
- 엔티티에 관한 속성 데이터들을 DB 상 한 릴레이션에 정보 구분하여 저장/관리
- 한 엔티티에 대한 하나의 릴레이션 테이블 구성함
- 릴레이션 = (스키마 + 인스턴스) 조합
3) 스키마
- 테이블의 헤더 부분
- 릴레이션의 기본 구조 뼈대 정의된 부분
4) 인스턴스
- 테이블 상의 실질적인 데이터 집합들
(a) 속성 | Attribute
- 릴레이션 테이블 상의 열 부분 ex. 성별
- 도메인 : 각 속성이 가질 수 있는 값의 범위 ex. 성별 = {남성, 여성}
- 차수 : 속성의 전체 개수 (잘 안변함)
(b) 튜플 | Tuple
- 릴레이션 테이블 상의 행 부분 - 카디널리티 : 튜플의 전체 개수 (잘 변함)
→ 여러 테이블들의 관계를 보자.
[테이블 간의 관계]
- 데이터베이스에는 여러 개의 테이블이 존재하고, 테이블 간에는 서로의 관계가 정의되어 있다.
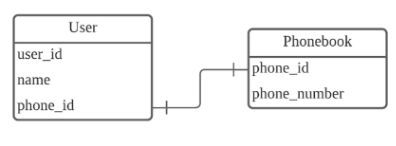
1) 1:1 관계
하나의 레코드가 다른 테이블의 레코드 한 개와 연결된 경우
이 구조에선 한 사용자는 하나의 전화번호를 갖고, 반대도 동일한 관계를 가지므로 1:1 관계이다.
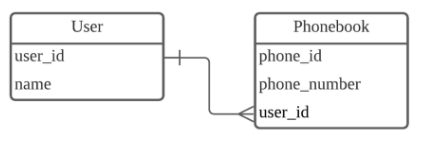
2) 1:N 관계
하나의 레코드가 서로 다른 여러 개의 레코드와 연결된 경우
이 구조에선 한 사용자가 여러 개의 전화번호를 가질 수 있지만, 여러 명의 사용자가 하나의 번호는 가질 수 없는 구조이다. (반대는 안되는 구조)
3) N:M 관계
여러 개의 레코드가 다른 테이블의 여러 개 레코드와 관련있는 경우
- 보통 두 테이블 직접 연결 X. 각 테이블의 PK를 FK로 참조하고 있는 (매핑(연결) 테이블) 사용함
- 즉, 양쪽 두 테이블과 1:N 관계 형성하는 새로운 테이블로 N:M 관계를 나타낸다.
ex. 학생이 여러 강의를 수강하지만, 강의도 여러 학생을 수용한다.
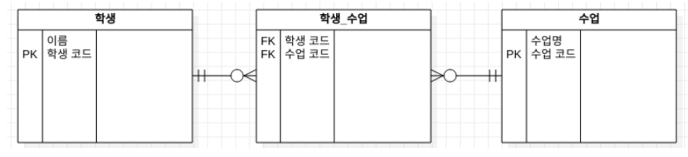
키 | Key (슈퍼키, 후보키, 기본키, 외래키, 대체키)
- 정의 : 릴레이션에서 특정 튜플(Tuple) 식별 시 사용하는 속성(Attribute) 집합이다.
- 각 튜플 유일 식별 장치
- 릴레이션 간의 관계 알려주는 장치
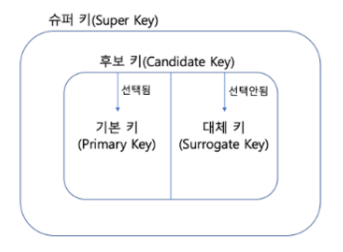
[키의 종류]
1) 슈퍼키
각 행을 유일하게 식별할 수 있는 속성들의 집합유일성만 만족하면 모두 슈퍼키
2) 후보키
각 행 유일하게 식별할 수 있는 최소한의 속성 집합기본키 될 수 있는 여러 후보키 (유일성, 최소성 동시 만족 키)
3) 기본키 PK
여러 후보키 中 선정된 대표키Null 값 가질 수 없고, 중복 안되고, 테이블 당 1개의 PK만 존재
→ 인조키(대리키) : 기본키 마땅한 속성 없을 때, 일련번호 인위적 생성한 기본키
→ 자연키 : 여러 속성 중 중복 X 자연스레 뽑아나온 기본키
4) 외래키 FK
다른 테이블의 기본키를 참조 or 자기 자신 PK를 참조하는 참조키Null 값 가질 수 있고, 테이블 당 여러 개 FK 존재 가능개체 간 관계 식별 시 사용 多
5) 대체키
후보키들 중 기본키로 선정되지 않은 후보키들
데이터 베이스 쿼리 | SQL
- SQL 에는 데이터 정의어(DDL), 데이터 조작어 (DML), 데이터 제어어 (DCL) 로 나뉜다.
- DBMS는 SQL문 해석하고 프로그램으로 변환하여 실행한 후 결과를 알려준다.
1) DDL 정의어 | Definition
- 테이블 구조 생성,수정,삭제
- CREATE, ALTER, DROP
2) DML 조작어 | Manipulaion
- 테이블 내의 대상 데이터 검색/삽입/수정/삭제
3) DCL 제어어 | Control
- 데이터 무결성 유지, 데이터 사용 권한 관리
- commit, rollback, grank, revoke 등
⬛ 데이터 조작어 (검색/삽입/수정/삭제)
데이터 검색 : SELECT 문 (= 질의어)
SELECT [ALL | DISTINCT] 속성리스트
FROM 테이블리스트
[WHERE 조건]
[GROUP BY 속성리스트 [HAVING 조건]]
[ORDER BY 속성리스트 [ASC | DESC]]
데이터 삽입 : INSERT 문
기존 테이블에 새 튜플(행) 추가하는 명령어
INSERT INTO 테이블이름(속성 리스트)
VALUES (값 리스트);
데이터 수정 : UPDATE 문
UPDATE 테이블이름
SET 속성1=속성값1, 속성2=속성값2, ...
[WHERE 조건];
데이터 삭제 : DELETE 문
DELETE
FROM 테이블이름
[WHERE 조건];
→ 이 중 ‘데이터 검색’에 해당하는 SQL 질의와 관련한 전반 문법을 정리했다.
1. 기본 검색
(1) 기본 검색
ex. 모든 도서의 이름, 가격 검색하시오
SELECT bookname, price
FROM Book;
(2) 중복 제거 | DISTINCT 키워드
ex. 도서 테이블에 있는 모든 출판사 (중복 없이) 검색하시오.
SELECT DISTINCT publisher
FROM Book;
2. 조건 검색 | WHERE 조건
- 조건에 맞는 검색을 위해 WHERE 절사용

(1) 단순 비교 | =, <, >, ≤, ≥
ex. 가격이 20,000원 미만인 도서 검색하시오.
SELECT *
FROM Book
WHERE price <= 20000;
(2) 범위 | BETWEEN 연산자
ex. 가격이 10,000원 이상 20,000이하인 도서 검색하시오.
SELECT *
FROM Book
WHERE price BETWEEN 10000 AND 20000;
//= (WHERE price >= 10000 AND price <= 20000);
(3) 집합 | IN 연산자, NOT IN 연산자
- WHERE 절에서 같은 속성 내부에 여러 값 비교 시 적합
ex. 출판사가 ‘굿스포츠’ 혹은 ‘대한미디어’인 도서 검색하시오 | IN 연산자
SELECT *
FROM Book
WHERE publisher IN ('굿스포츠', '대한미디어');
ex. 출판사가 ‘굿스포츠’ 혹은 ‘대한미디어’가 아닌 도서 검색하시오 | OUT 연산자
SELECT *
FROM Book
WHERE publicher NOT IN ('굿스포츠', '대한미디어');
(4) 문자열 패턴 비교 | LIKE 연산자

ex. “축구의 역사”를 출간한 출판사 검색하시오
SELECT bookname, publisher
FROM Book
WHERE bookname LIKE '축구의 역사';
→ 일부 문자열 포함한 비교 | LIKE ‘%문자%’
ex. 도서 이름에 ‘축구’가 포함된 출판사 검색하시오
SELECT bookname, publisher
FROM Book
WHERE bookname LIKE '%축구%';
→ 특정 위치 한 문자 대신 비교 | (_) 밑줄 문자
ex. 도서 이름 왼쪽 두 번째 위치에 ‘구’ 포함하는 도서 검색하시오
SELECT *
FROM Book
WHERE bookname LIKE '_구%';
(5) 복합 조건 검색 | 논리 연산자 (AND, OR, NOT)
→ AND
ex. 축구에 관한 도서 중에서 가격이 20,000원 이상인 도서 검색하시오
SELECT *
FROM Book
WHERE bookname LIKE '%축구%' AND price >= 20000;
→ OR
ex. 출판사가 ‘굿스포츠’ 혹은 ‘대한미디어’인 도서 검색하시오
SELECT *
FROM BOok
WHERE publisher = '굿스포츠' OR publisher = '대한미디어';
(6) 검색 결과의 정렬 | ORDER BY절
- 특정 순서대로 결과를 출력할 때 사용
→ ORDER BY : 기본 오름차순 ASC 이다. (내림차순 DESC 키워드 사용해야 함)
ex. 도서를 이름 순으로 검색하시오.
SELECT *
FROM Book
ORDER BY bookname;
ex. 도서를 가격 순으로 검색하고, 가격이 같으면 이름순으로 검색하시오.
SELECT *
FROM Book
ORDER BY price, bookname;
ex. 도서를 가격 내림차순으로 검색하는데, 가격이 같다면 출판사 이름 오름차순으로 출력하시오.
SELECT *
FROM Book
ORDER BY price DESC, publisher ASC;
3. 집계 함수의 사용

(1) SUM
ex. 2번 고객이 주문한 도서의 총판매액을 출력하고, 별칭은 ‘총매출’로 출력하시오
SELECT SUM(saleprice) AS 총매출 **//속성 이름 별칭 지칭 키워드**
FROM Orders
WHERE custid = 2;
(2) AVG, MIN, MAX
ex. 고객이 주문한 도서의 (총판매액, 평균값, 최저가, 최고가)를 구하시오
SELECT SUM(saleprice) AS Total,
AVG(saleprice) AS Average,
MIN(saleprice) AS Minimum,
MAX(saleprice) AS Maximum
FROM Orders;
(3) COUNT | 행의 개수 센다.
ex. 마당서점의 도서 판매 건수를 구하시오.
SELECT COUNT(*)
FROM Orders;ex. 마당서점의 (중복 제거)하여 출판사 수를 구하시오
SELECT COUNT (DISTINCT(publisher)),
FROM Book;
(4) Group By 절 | 그룹화 시킴 (-별로)
ex. 고객별로 주문한 도서의 총수량과 총판매액을 구하시오.
→ 각 고객 id별로 (주문한 총수량, 총판매액) 구해짐
SELECT custid, COUNT(*) AS 도서수량, SUM(saleprice) AS 총액
FROM Orders
GROUP BY custid;
(5) HAVING 절 | GROUP BY 로 그룹화한 것에 대한 조건 표시
- HAVING은 조건절이라 WHERE 뒤에 있어야 하고,
- 검색 조건에는 (집계 함수) 와야 함 | SUM, COUNT, MAX, MIN, COUNT 등
ex. 가격 8000원 이상인 도서를 구매한 고객에 대하여, 고객별 주문 도서의 총수량을 구하시오.
(단, 2권 이상 구매한 고객만 구하시오.)
SELECT custid, COUNT(*) AS 도서수량
FROM Orders
WHERE saleprice>=8000
GROUP BY custid
HAVING count(*) >=2;[여러 개 테이블에 대한 SQL 질의] : 조인, 부속 질의
4. 조인 검색
여러 개의 테이블을 단일 테이블로 만드는 연산
- 이 때, 여러 개의 테이블을 연결할 수 있는 ‘속성’이 필요하다. (= 조인 속성)
- 조인 속성의 이름은 달라도 되지만, 도메인은 같아야 한다.
- 일반적으로 FK(외래키)를 조인 속성으로 이용한다.
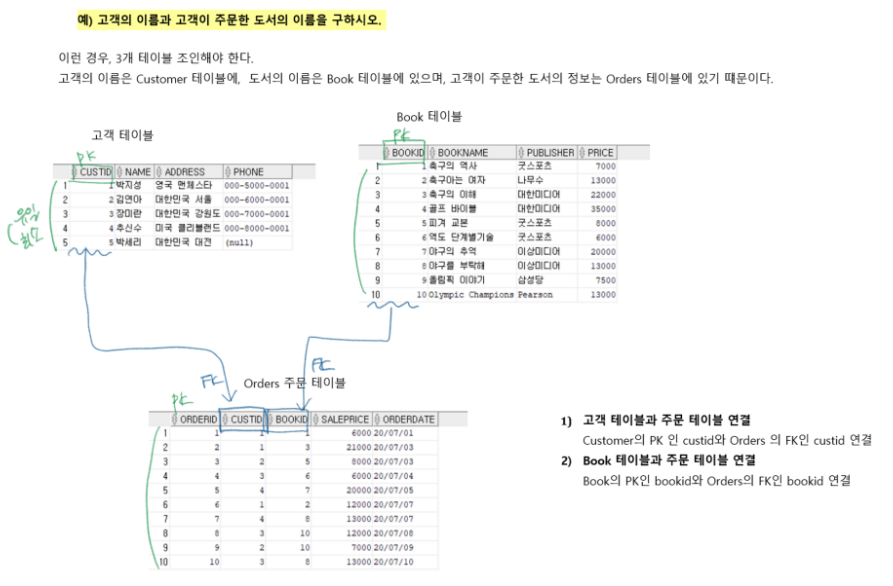
🎈 아래처럼 Customer, Book, Orders 테이블 3개가 존재한다고 가정하고 설명한다.
⬛ 내부 조인 | inner Join (교집합) 조인
- 기준 테이블과 JOIN 테이블의 중복된 값을 보여주는 조인
1) 동등 조인 : 동등 조건을 기준 조인
ex. 고객 이름과 고객이 주문한 도서의 판매 가격을 검색하시오.
//고객 이름 = Customer, 고객의 주문 정보 = Orders에 있음
SELECT name, saleprice
FROM Customer, Orders
WHERE Customer.custid = Orders.custid; //동등 조인
ex. 고객별로 주문한 모든 도서의 총판매액을 구하고, 고객별로 정렬하시오.
SELECT name, SUM(saleprice) //이름, 총판매액
FROM Customer, Orders
WHERE Customer.custid = Orders.custid //테이블 조인
GROUP BY Customer.name //고객별
ORDER BY Customer.name; //정렬
ex. 가격이 20,000원인 도서를 주문한 고객의 이름과 도서의 이름을 구하시오.
//고객 주문 정보는 Orders 에 있지만
고객 이름과 책 이름이 각각 Customers, Book 에 있기 때문에
총 3개의 테이블을 조인해야 한다.이때 Orders의 FK에 각각의 PK를 매핑시켜 조인한다.
SELECT Customer.name, Book.bookname
FROM Customer, Orders, Book
WHERE Customer.custid = Orders.custid AND Orders.bookid = Book.bookid
AND Book.price = 20000;
2) INNER JOIN 활용 문법

SELECT *
FROM TableA A
INNER JOIN TableB B
ON A.key = B.key
⬛ 외부 조인
- 두 테이블 중 한쪽에만 데이터 있어도 나온다.
- 조인 후 해당 항목 없으면 NULL 로 표시됨
1) LEFT OUTER JOIN
- 왼쪽 테이블 기준으로 JOIN 모든 값 보여주고, (오른쪽 테이블은 공통된 값 있는 것만 보여줌)
→ 따라서, 오른쪽 테이블에 매핑된 값 없을 경우 NULL로 채움

SELECT *
FROM TableA A
LEFT JOIN TableB B
ON A.key = B.key
ex. 도서 구매하지 않은 고객 포함하여 고객 이름과 고객이 주문한 판매 가격 구하시오.
SELECT Customer.name, saleprice
FROM Customer LEFT OUTER JOIN Orders
ON Customer.custid = Orders.custid;
2) RIGHT OUTER JOIN
- 오른쪽 테이블 기준으로 JOIN 모든 값 보여주되 (왼쪽 테이블은 공통된 값 있는 것만 보여줌)
→ 따라서, 왼쪽 테이블에 매핑되는 값 없을 경우 NULL로 채움
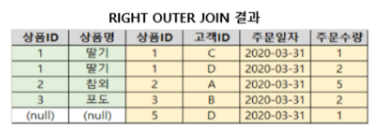
SELECT * FROM TableA A
RIGHT JOIN TableB B ON
A.key = B.key
3) FULL OUTER JOIN
- 왼쪽과 오른쪽 테이블 합칩합
- 두 테이블의 모든 값들을 보여줌
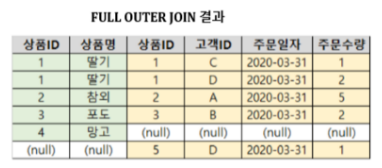
SELECT * FROM TableA A
FULL OUTER JOIN TableB B ON
A.key = B.key
4) FULL ONLY OUTER JOIN
- 교집합 제외 FULL
- 두 테이블의 공통된 부분 제외하고 보여줌
SELECT * FROM TableA A
FULL OUTER JOIN TableB B ON
A.key = B.key WHERE A.key IS NULL
OR B.key IS NULL
⬛ 추가 조인
1) CROSS JOIN
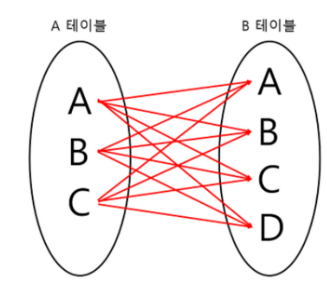
모든 경우의 수를 전부 표현해주는 방식이다.
A가 3개, B가 4개면 총 3*4 = 12개의 데이터가 검색된다.
SELECT
A.NAME, B.AGE
FROM EX_TABLE A
CROSS JOIN JOIN_TABLE B
2) SELF JOIN
- 자기 자신과 조인
- 하나의 테이블을 여러번 복사해서 조인한다고 생각하면 편하다.
- 자신이 갖고 있는 칼럼을 다양하게 변형시켜 활용할 때 사용한다.
SELECT
A.NAME, B.AGE
FROM EX_TABLE A, EX_TABLE B
3) 자연 조인
- 동등 조인에서 조인에 참여한 속성들 중 (중복 속성) 제거한 결과 반환
4) 세미 조인
- 자연조인 한 후 두 릴레이션 중 한쪽 릴레이션의 결과만 반환
5. 부속 질의 이용한 [검색]
- 부속 질의 = SQL문 안에 다른 SQL문이 중첩된 질의
→ 부속 질의를 활용한 데이터 검색
: WHERE 절에 또 다른 테이블 결과를 이용하려고 다시 SELECT 문을 괄호로 묶는다.
- 1) 부속 질의 먼저 처리 → 2) 전체 질의 처리
ex. 가장 비싼 도서의 이름을 보이시오.
//모두 Book 테이블 상에 있지만, 가장 비싼 가격에 해당하는 책 이름을 추출해야 한다.
→ ‘가장 비싼 가격’ 찾기 위해 부속 질의 처리 후, 그 값에 해당하는 bookname을 추출함
SELECT bookname
FROM Book
WHERE price = (SELECT MAX(price) FROM Book);❓ 조인 vs 부속 질의
→ 일반적으로 여러 테이블 연관 시킬 때 데이터 대량인 경우,
데이터를 모두 합치는 조인 보다는 필요한 데이터만 찾아서 공급해주는 부속 질의 성능이 더 좋다.
1) 조인 사용 : Customer 테이블과 Orders 테이블을 고객 번호로 조인한 후→ 필요 데이터 추출]
즉, 조인은 모두 합친 뒤 필요 데이터를 추출한다.
2) 부속 질의 사용 : Customer 테이블에서 박지성 고객의 고객번호 (일부) 찾고, 찾은 고객 번호 바탕으로 Orders 테이블에서 확인
즉, 부속 질의는 애초에 필요한 데이터 추출 한 뒤, 원하는 데이터 재추출
6. 여러 테이블 간의 집합 연산 | 교집합, 합집합, 차집합
- 교집합 | INTERSECT
- 합집합 | UNION
- 차집합 | MINUS
ex. 도서 주문하지 않은 고객의 이름을 보이시오.
// 모든 고객 - (주문한 고객) = 주문하지 않은 고객
SELECT name
FROM Customer
MINUS // 빼기
SELECT name
FROM Customer
WHERE custid IN (SELECT custid FROM Orders);
7. EXISTS | 상관 부속질의문
- 조건에 맞는 투플이 존재하면 결과에 포함시킨다.
ex. 주문이 있는 고객의 이름과 주소를 보이시오.
SELECT name, address
FROM Customer ct
WHERE EXISTS (SELECT * FROM Orders od WHERE cs.custid = od.custid);[추가] SELECT 쿼리의 수행 순서
FROM 보고, WHERE 조건 보고, GROUP BY 보고, HAVING 보고, SELECT 한 상태에서, ORDER BY 함
FROM, ON, JOIN
>> WHERE, GROUP BY, HAVING
>> SELECT
>> DISTINCT
>> ORDER BY
>> LIMIT⬛ 데이터 정의어 (테이블 생성/변경/삭제)
- 테이블의 구조를 정의
1) 테이블 생성 | CREATE 문
- PK 지정
CREATE TABLE 테이블 이름[(속성리스트)]
AS SELECT 문
[WITH CHECK OPTION];
//예시
CREATE TABLE NewBook (
bookid NUMBER,
bookname VARCHAR(20),
publisher VARCHAR(20),
price NUMBER,
PRIMARY KEY (bookid)); //PK 지정
2) 테이블 수정 | ALTER 문
이미 생성된 테이블의 속성 변경이나 제약을 변경
ALTER TABLE 테이블이름
[ADD] 속성 추가
[DROM COLUMN] 속성 제거
[ALTER COLUMN] 속성 대체
[ALTER COLUMN] 속성이름 NULL/NOT NULL
[ADD PRIMERY KEY] 기본키 추가
[ADD | DROP] 제약사항 추가 /삭제
3) 테이블 전체 삭제 | DROP문
데이터만 삭제하고 싶으면 DELETE문 사용
테이블 전체 삭제는 DROP문
DROP TABLE 테이블이름;
⬛ SQL 내장 함수
1. 숫자 함수
1) 절댓값 함수 : ABS 함수
ex. -78과 78의 절댓값 구하시오.
SELECT ABS(-78), ABS(+78)
FROM Dual;
2) 반올림 함수 : ROUND 함수
ex. 4.753을 소수 첫째 자리에서 반올림한 값을 구하시오.
SELECT ROUND(4.753, 1)
FROM Dual;
→ 함수를 복합적으로 사용도 가능
ex. 고객별 평균 주문 금액을 백 원 단위로 반올림한 값을 구하시오.
//속성 옆에 “열이름” 지정하면 속성 이름 변경되어 출력된다.
//또한, ROUND 함수 -2로 지정되면 백원 단위의 반올림이 된다.
SELECT custid "고객번호", ROUND( SUM(saleprice) /COUNT(*), -2) "평균금액"
FROM Orders
GROUP BY custid;
2. 문자 함수
- 문자열 가공한 결과 반환
1) 데이터 문자열 치환하는 함수 : REPLACE 함수
ex. 도서 제목에 ‘야구’가 포함된 도서를 ‘농구’로 변경한 후 도서 목록을 보이시오.
SELECT bookid, REPLACE(bookname, '야구', '농구') bookname, publisher, price
FROM Book;
//REPLACE 함수는 bookname 속성에 있는 ‘야구’ → ‘농구’ 이름 치환시키고
//속성명을 bookname으로 재지정했다.
2) 글자 수 세기 | LENGTH 함수
- 글자 수 센다. cf. 바이트 수 세기 (LENGTHB 함수)
- 공백도 하나의 문자로 간주하여 센다.
ex. ‘굿스포츠’에서 출판한 도서 제목과 제목의 글자 수, 바이트 수 보이시오.
SELECT bookname "제목", LENGTH(bokname) "글자수", LENGTHB (bookname) "바이트수"
FROM Book
WHERE publisher = '굿스포츠';
3) 문자열 특정 위치에서 시작하여 지정 길이만큼 문자열 반환 | SUBSTR 함수
- substring 준말
ex. 마당서점 고객 중 같은 ‘성씨’ 가진 사람 몇 명인지 성별 인원 수 구하시오.
SELECT SUBSTR(name, 1,1) "성", COUNT(*) "인원"
FROM Customer
GROUP BY SUBSTR(name, 1, 1);
3. 날짜/시간 함수
(1) TO_DATE 함수 | 문자형 데이터 → DATE 형으로 반환
(2) TO_CHAR 함수 | DATE 형 데이터 → 문자형 데이터로 반환
(3) 날짜형 대상 +, - 연산
→ 원하는 날짜 이전(-), 이후(+) 계산 가능
ex/ 2020년 7월 1일의 5일 전, 5일 후는 다음과 같이 구할 수 있다.
SELECT TO_DATE('2020-07-01', 'yyyy-mm-dd') - 5 BEFORE,
TO_DATE('2020-07-01', 'yyyy-mm-dd') + 5 BEFORE,(4) 현재 날짜 출력 함수 | SYSDATE 함수, SYSTIMESTAMP 함수
→ SYSDATE 함수 : 현재 날짜 시간 반환
→ SYSTIMESTAMP 함수 : 현재 날짜, 시간, 초 이하의 시간, 서버 TIMEZONE 출력
4. NULL값 처리
1) NULL 여부 확인 | IS NULL, IS NOT NULL
- null인 데이터나 null이 아닌 데이터 추출 시 활용
2) NVL 함수
- null 데이터를 다른 임의의 값으로 대체함
- NVL (속성, 대체값) ;/ /해당 속성에 있는 null 데이터를 대체값으로 출력
[추가] 부속 질의
- 부속 질의는 SQL문 안에 다른 SQL문이 중첩된 질의
- 부속 질의 위치와 역할에 따라 SELECT 부속질의/ FROM 부속질의/WHERE 부속질의 구분
1) 스칼라 부속 질의 | SELECT 부속 질의
- 부속 질의가 SELECT 절에서 사용됨
- 단일값 반환하기 위해 사용하기 때문에 스칼라 부속 질의라고 한다.
ex. 고객별 판매액을 보이시오. (고객이름과 고객별 판매액 출력)
SELECT (SELECT name FROM Customer cs
WHERE cs.custid = od.custid) "name", SUM(saleprice) "total"
FROM Orders od
GROUP BY od.custid;2) 인라인 뷰 | FROM 부속 질의
- 부속 질의가 FROM 절에서 사용됨
- 결과를 뷰의 형태로 반환하기 때문에 인라인 뷰
뷰 : 전체 테이블의 일부만 보여준다. 기존테이블에서 일시적으로 만들어진 가상 테이블 의미
ex. 고객번호가 2 이하인 고객의 판매액을 보이시오. (고객이름, 고객별 판매액 출력)
SELECT cs.name, SUM(od.saleprice) "total"
FROM (SELECT custid, name
FROM Customer
WHERE custid <=2) cs, Orders od
WHERE cs.custid = od.custid
GROUP BY cs.name;3) 중첩 질의 | WHERE 부속 질의
- 부속 질의가 WHERE 절에서 사용됨
- 결과 한정시키기 위해 사용한다.
ex. 평균 주문 금액 이하의 주문에 대해서 주문번호와 금액 보이시오.
SELECT orderid, saleprice //주문번호, 금액 뽑음
FROM Orders
WHERE saleprice <= (SELECT AVG(saleprice) //평균 이하의 주문 금액에서
FROM Orders);[추가] 조인의 원리
- 조인의 원리는 중첩 루프 조인/정렬 병합 조인/해시 조인 등이 있다.
1) 중첩 루프 조인 (NLJ) Nested Loop Join
- 중첩 for문과 같은 원리로 조건에 맞는 조인 하는 방법이다.
- 랜덤 접근 시 비용 많이 증가하므로 대용량 테이블에서느 사용X
(첫 테이블 행을 한 번에 하나씩 읽고, 그 다음 테이블에서도 행을 하나씩 읽어 조건에 맞는 레코드 찾아 결과값 반환한다.)
for each row in t1 matching reference key {
for each row in t2 matching reference key {
if row satisfies join conditions, send to client
}
}
2) 정렬 병합 조인
- 각각의 테이블을 조인할 필드 기준으로 정렬하고, 정렬 끝난 이후 조인 작업 수행하는 조인
3) 해시 조인
- 해시 테이블 기반으로 조인하는 방법
- 보통 중첩 루프 조인보다 효율적
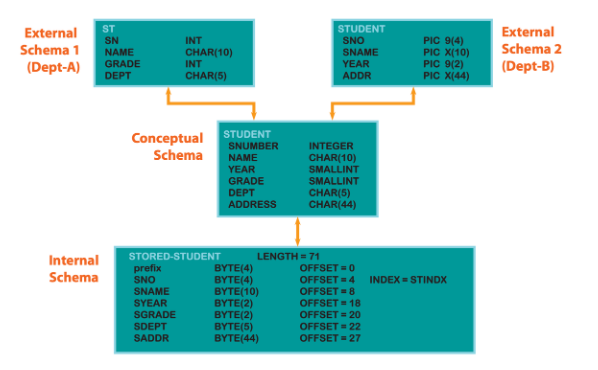
[추가] 스키마의 정의
* 스키마 : DB 구조와 제약조건에 관한 전반적 명세 기술한 것
1. 외부 스키마 : 사용자가 보는 데이터 (사용자가 필요한 일부분 보여주는 뷰). 서브 스키마 = View (뷰)
2. 개념 스키마 : DB 전체 논리적 구조. 전체적인 뷰 (조직체 전체를 관장하는 입장에서 DB 정의한 것)
개념 스키마가 일반적인 DB 전체 테이블 상의 헤더 (스키마)를 의미한다고 함 (전체 DB 논리적 구조)
3. 내부 스키마 : 물리적인 저장장치(하드디스크) 상에서 DB가 저장되는 방법을 기술한 것
'[스터디] CS 기술 면접 준비 > CS_데이터베이스 [DataBase]' 카테고리의 다른 글
| 12회차 데이터베이스 | DB 인덱스(B-Tree, B+Tree, 해쉬테이블), DB 튜닝, DB 다중화 질문 정리 (67) | 2024.02.13 |
|---|---|
| 12회차 데이터베이스 | DB 인덱스(B-Tree, B+Tree, 해쉬테이블), DB 튜닝, DB 다중화, 내용 정리 (62) | 2024.02.12 |
| 11회차 데이터베이스 | 정규화와 역정규화 관련 질문 내용 정리 (83) | 2024.02.07 |
| 11회차 데이터베이스 | 정규화와 역정규화 관련 내용 정리 (58) | 2024.02.05 |
| 10회차 데이터베이스 | 데이터베이스 개요 및 쿼리 관련 질문 정리 (0) | 2024.02.02 |